
Page 101 - 《党政研究》2026年第3期
P. 101
上述城市的教育支出、医疗卫生支出、就业与社会保障支出等作为公共服务支出的核心组
成部分,其总和作为衡量公共服务供给水平的核心指标。为了避免数值过大进而产生估计
误差,本文对被解释变量进行了对数化处理。从计量操作的科学性原则来看,取对数可以
视为 “不改变原始数据相对大小的单调变换”,取对数本身也不会改变变量间的相关性,
因此取对数则是对正常数据的保护,能避免线性回归时参数估计被个别异常值绑架。交互
项 Treat × Post 的系数是本文的核心观察指标,反映了 2021 年政策强化对核心圈层城市
i
t
绩效的影响。其中 Treat 是组别虚拟变量,Post 是时间虚拟变量。此外,模型引入了城市
i t
,旨在排除个体异质性与时间共同趋势的干扰,从而精准
固定效应 μ i 与年份固定效应 λ t
识别协同政策的净效应。
( 3)平行趋势检验
DID 模型成立的前提是实验组与对照组在政策干预前满足平行趋势。通过对 2013 -
2021 年两组样本的动态观察,核心圈层城市与对照组城市在公共服务支出上的变化轨迹
基本平行,未出现显著的系统性差异 (如图 4)。这证明了若无 2021 年的政策强化,两组城
市的发展趋势将保持一致。此外,实验组城市均与武汉地理接壤,处于 “一小时通勤圈”
内,这种空间上的连续性进一步增强了因果识别的 “可证成性”。进一步回归分析 (图 5)
显示,在政策实施前,指标回归系数置信区间经过 0 点,满足了平行趋势的假设条件。
( 4)因果识别 ( DID)结果
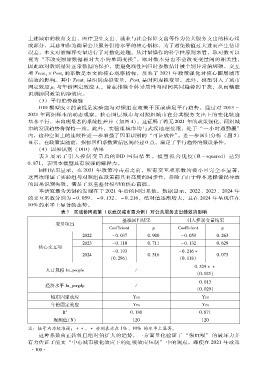
表 3 展示了引入控制变量后的DID 回归结果。模型拟合优度( R - squared)达到
0. 871,表明本模型具有较强的解释力。
回归结果显示,在 2021 年政策冲击点之前,所有交互项系数均极小且完全不显著,
这再次印证了实验组与对照组在政策前具有高度的同步性,排除了由于样本选择偏误导致
的因果识别失效,满足了双重差分模型的核心前提。
本研究最为关键的发现在于 2021 年后的回归系数。数据显示,2022、2023、2024 年
的交互系数分别为 - 0. 059、 - 0. 132、 - 0. 216,绝对值逐渐增大,且在 2024 年呈现住在
10%的水平上显著的态势。
表 3 区域协同政策 (以武汉城市圈为例)对公共服务支出绩效的影响
基准回归结果 引入控制变量结果
变量项目
Coefficient p Coefficient p
2022 - 0. 037 0. 900 - 0. 059 0. 263
核心交互项 2023 - 0. 110 0. 711 - 0. 132 0. 629
- 0. 193 - 0. 216
( 0. 296) ( 0. 118)
2024 0. 516 0. 073
0. 529
( 0. 025)
人口规模 In_people /
0. 013
( 0. 029)
经济水平 In_pergdp /
城市固定效应 Yes Yes
年份固定效应 Yes Yes
R 2 0. 180 0. 871
观测值( N) 120 120
注:括号内为标准误;、 分别表示在 1%、10% 的水平上显著。
这种系数由正转负且绝对值扩大的趋势,一方面量化验证了 “强虹吸”的破坏力并
有力佐证了前文 “中心城市极化效应下的虹吸效应压制”中的观点。即使在 2021 年政策
1 0 · 0 ·