
Page 85 - 《社会》2016年第3期
P. 85
社会· 2016 · 3
佳整体匹配这三种具体方法进行倾向值匹配分析。
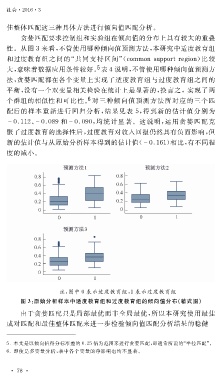
贪婪匹配要求控制组和实验组在倾向值的分布上具有较大的重叠
性。从图 3 来看,不管使用哪种倾向值预测方法,本研究中适度教育组
和过度教育组之间的“共同支持区间”( 犮狅犿犿狅狀狊狌 狆狆 狅狉狋狉犲 犵 犻狅狀 )比较
大,意味着数据应用条件较好。 5 表 4 说明,不管使用哪种倾向值预测方
法,贪婪匹配都在各个变量上实现了适度教育组与过度教育组之间的
平衡,没有一个双变量相关检验在统计上是显著的,换言之,实现了两
个群组的相似性和可比性。 6 对三种倾向值预测方法所对应的三个匹
配后的样本重新进行回归分析,结果见表 5 ,得到新的估计值分别为
-0.112 、 -0.089 和 -0.090 ,均统计显著。这说明,运用贪婪匹配克
服了过度教育的选择性后,过度教育对收入回报仍然具有负面影响,但
新的估计值与从原始分析样本得到的估计值( -0.161 )相比,有不同程
度的减小。
注:图中 0 表示适度教育组, 1 表示过度教育组
图 3 :原始分析样本中适度教育组和过度教育组的倾向值分布(箱式图)
由于贪婪匹配只是局部最优而非全局最优,所以本研究使用最佳
成对匹配和最佳整体匹配来进一步检验倾向值匹配分析结果的稳健
5. 本文是以倾向值得分标准差的 0.25 倍为范围来进行贪婪匹配,即通常所说的“半径匹配”。
6. 即使是多变量分析,表中各个变量的净影响也均不显著。
· 7 8 ·